Mumble removed noise cancelling (and what to do about it)
Mumble is an open-source VoIP application, very similar to TeamSpeak in its functionality. Like most VoIP applications, a noise suppression functionality is very much needed, otherwise conversations with multiple people quickly devolve into a cacophony of noise, including, but definitely not limited to, chewing, knuckle cracking, open-mouth breathing, burping, farting, all layered with the creaking of office chairs and typing on mechanical keyboards with clicky switches.
Noise be gone
NOTICE
Mumble reverted their decision and reintroduced RNNoise. If you still want better noise canceling (not only for mumble), read on :)
Mumble, for the longest time, had two different noise suppression modes: Speex and RNNoise.
In my experience, Speex has never been very capable and is easily surpassed by RNNoise in functionality, so let’s look at RNNoise:
RNNoise is pretty good at filtering out background noise, so that the microphone would (mostly) only activate when you were actually talking. The voice activation is still based on loudness, so if you open a bag of chips next to your microphone it would still activate. General background noise like keyboard and mouse clicking is filtered out in most cases though. All in all a very usable noise suppression algorithm.
RNNoise be gone??
Mumble released version 1.5.613 (RC 2) on March 3rd, 2024, and with it came one drastic decision: RNNoise isn’t included in the default builds anymore, effectively removing the feature. The developers explain why in this pull request. The tldr is that RNNoise causes a lot of hard to debug issues and the sole developer handling these bug reports is, frankly said, sick of it, so he disabled RNNoise in the distributed binaries. IMHO perfectly reasonable because (just as a friend said to me when I told him about the changes): Open Source Maintainers Owe You Nothing.
While you still can build Mumble yourself with RNNoise enabled, it doesn’t seem realistic for the average user to do that. That makes the removal of RNNoise a major regression for most users (again, no gripes, just an observation) and made me recommend not to update their client to the users of my Mumble server.
Furthermore, RNNoise does not work at all under macOS, it even crashes the client when selected. A complete replacement of RNNoise seems like the best solution overall. There are efforts in that regard being made by the Mumble developers, but it will still take a lot of time and work for any results.
DeepFilterNet to the rescue
There are, of course, different noise suppression tools available. One that is in a usable (and very capable) state is DeepFilterNet. You can see (hear) examples of how well it works on the projects GitHub page, and oh boy, does it work well. It eliminates virtually everything that isn’t a human voice, be it white noise or harmonics (you can play the guitar while having a chat!). Additionally, DeepFilterNet is available as a PipeWire plugin, making it easy to integrate into an existing Linux setup. Seems like an ideal candidate to replace RNNoise, so let’s try to do that!
Installing and configuring DeepFilterNet
Clone the repository and build the plugin
git clone https://github.com/Rikorose/DeepFilterNet.git
cd DeepFilterNet
cargo build --release -p deep-filter-ladspa The compiled plugin can now be found at ./target/release/libdeep_filter_ladspa.so
Create the configuration and its directory
mkdir /etc/pipewire/filter-chain.conf.dcontext.modules = [
{ name = libpipewire-module-filter-chain
args = {
node.description = "DeepFilter Noise Canceling Source"
media.name = "DeepFilter Noise Canceling Source"
filter.graph = {
nodes = [
{
type = ladspa
name = "DeepFilter Mono"
plugin = /usr/lib/ladspa/libdeep_filter_ladspa.so
label = deep_filter_mono
control = {
"Attenuation Limit (dB)" 100
}
}
]
}
audio.rate = 48000
audio.position = [FL]
capture.props = {
node.passive = true
}
playback.props = {
media.class = Audio/Source
}
}
}
]Install the plugin (copy it to the correct location)
mkdir /usr/lib/ladspa
cp ./target/release/libdeep_filter_ladspa.so /usr/lib/ladspa/Run the DeepFilter
pipewire -c filter-chain.confA new virtual input device should now be available:
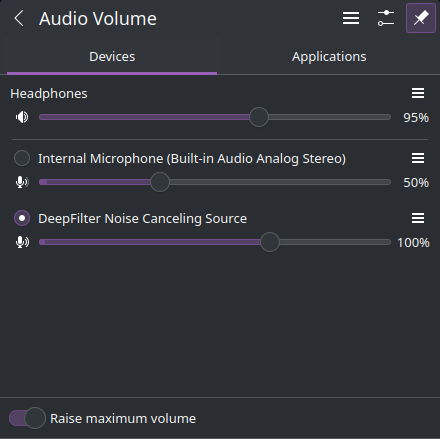
Configuring Mumble
Now we need to tell Mumble to use the correct input device. In my case it didn’t select the filtered input automatically, but it also doesn’t list any inputs except Mono:
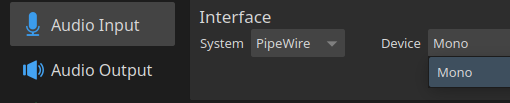
To fix that (at least under KDE Plasma) we have to explicitly select the input device for the Mumble application:
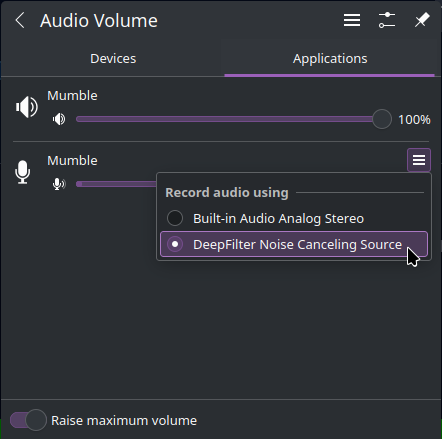
And that’s it, Mumble should now use the DeepFilter device as input!
Drawbacks
I am very happy with the current performance of DeepFilter. Nonetheless, there a few things to be aware of:
- In order to minimize underruns, DeepFilter introduces a latency of ~40ms (in addition to any latency introduced by PipeWire).
- It is basically a neural net and as such, requires more processing power than traditional approaches to noise suppression. On an 8th Gen mobile Intel CPU it eats ~5-6% and 155 MB of RAM.
- I don’t know how well DeepFilterNet works for higher pitched voices (like, you know, women tend to have). A bias towards lower pitched voices is a well documented flaw of neural nets that were trained on insufficient datasets.
This problem is often exacerbated in open source projects, since most of the training data is produced by the developers and/or the people using the software. And because we, as a civilization, still haven’t overcome gender disparity, these neural nets tend to favor voices with a lower pitch.